300万行代码精简到30万! 腾讯新闻推选架构重构复盘
- 发布日期:2025-12-26 11:41 点击次数:130
一、“重构”的界说
二、重构决策:什么时候该动手
三、重构规模:平迁如故重建
四、重构策略:绞杀者模式的实战应用
五、风险为止:怎样保证不翻车
六、数据迁徙:最难啃的硬骨头
七、架构联想的底层原则
八、复盘与反想
任何业务系统重构里面最中枢的原则即是康威定律,即组织的雷同结构决定了业务系统的架构。换句话说组织架构要服务于合理的系统架构,业务重构发生前组织重构要先行。但是本文落脚点并不在于筹商公司治理的效率和组织智力,因而咱们假定公司的组织架构是有饱胀的效率和弹性的,业务系统重构自身并不受公司组织架构的制约。
一、“重构”的界说
“重构”在互联网里面还是成为了一个司空见惯的名词,在各个公司也算是一个须生常谭的问题。但是什么时候重构?为什么要重构?怎样重构?要修起好这些问题似乎又不是那么的肤浅,今天想通过我方曩昔作念过的几个案例跟行家分享一下我关于重构的一些领略。
泉源,咱们先肤浅界说一下“重构”,什么样的调动智力称之为“重构”呢?咱们尝试从范例联想这个微不雅层面来界说一下:重构是一种有表率、有组织、在不改变软件外部行动的前提下,改善其里面结构的代码修改方式。从这个角度来讲并非系数的代码调动都可以称之为“重构”,重构的行动自身必须恪守一定的原则,其中最关键的一丝即是不改变原有范例的observable behavior(外部的可不雅测性),肤浅来说即是:在重构前后,你的软件关于任何雷同的输入,都应该产生皆备雷同的输出。
但是在施行的业务场景中,系统的优化频频会横跨多个团队、多个模块、多种语言,因而咱们从宏不雅的视角来重新界说一下施行业务系统层面的重构:重构是在不改变系统外部可不雅察行动的前提下,通过改善其里面结构(代码、架构、数据模子),以汲引非功能性目的(如可人护性、推广性、性能),并为畴昔业务发展奠定坚实时候基础的系统性工程。
因而在业务系统的重构中一般来说不可变量为原有系统的功能性或者说业务经由的完整性,局部会要求接口的幂等性,但是具体到不同的业务场景不变性的拘谨又不尽雷同。
举个例子:假如咱们重构的是一个交游系统,那么里面不可变量就很是明确:通盘交游经由的完整性以及交游数据的幂等性即是一个强拘谨。
但是如果咱们纠正的是近似腾讯新闻这样的推选系统,这里面的不可变拘谨就变成了局部业务经由的完整性(东谈主工侵犯的有用性、内容时效性拘谨、负反馈的有用性等)以及业务系统中枢目的的褂讪性,全体而言关于不变性的拘谨会变弱。因而咱们得出另外一个关键的原则,在业务系统重构的过程中不变性拘谨的强弱和规模跟原有业务系统关于数据一致性要求的强弱和规模联系。
当今似乎咱们关于重构有了一个较为明确的界说,然后咱们尝试去修起第二个问题,为什么要去重构?其实在上述办法界说里面也可以寻得蛛丝马迹,一般来讲咱们可以抽象为两种情形:
1)当原有的系统在非功能性目的的各个维度上出现了较为严重的问题,进而影响了业务的功能性需求的时候,咱们就需要探求重构;
2)即是业务靠近转型期,中枢的功能定位产生了变化,原有系统还是不行够撑合手新的功能的演进。
在一个大的业务系统里面频频两种情况交叠出现。
21年底,我加入腾讯新闻,正值适逢腾讯新闻业务的转型期,按照新的业务标的来评估原有的业务系统是没办法得志个性化引擎驱动的社区内容分发的需求的,是以业务系统的重构近在咫尺。
说真话,刚拿到这个任务时,我的第一反应不是悦耳,而是懆急。这套系统还是褂讪运行了接近20年,同期系统的联想跟原有派系的居品形态是比较匹配的,每天服务大几千万用户,任何闪失都可能上热搜。但不重构又不行——老架构还是严重制约了业务发展,时候债像滚雪球一样越滚越大。
先说几个数字让行家感受一下其时的状态:2021年全年,推选系统激发事故屡次,可用性不及99%。存在200多个代码仓库、300多万行代码、2000多个物理服务,同期运营老本居高不下,爱护这套系统就像在泥潭里跋涉,在这种情况下重构就成为了大势所趋的遴荐。
咱们从系统非功能性目的来看,三个最径直的痛点:
1)性能瓶颈
推选系统最中枢的调回、排序链路,反映时期还是从最初的500ms飙到了1200ms+。咱们尝试过各式优化,该加的缓存加了,该拆的服务拆了,但收效甚微。根柢原因是架构联想时没探求到分发侧策略的复杂度比较原有运营驱动的体系有指数级的增多,单单一个精排模子的耗时就率先了200ms。更要命的是,系统里跑着400多个业务场景、1000多种推选策略,各个场景之间的复用程度极低,基本上是“一个场景一套服务”,资源控制率很差。
2)推广艰辛
居品司理隔三差五就提新需求:“能不行支合手多路调回?”“能不行加个实时特征?”“能不行作念个冷启动优化?”每个需求听起来都合理,但落到代码层面,牵一发而动全身。因为早期是单体架构,各个模块耦合严重,改一处代码要回想测试好几天。一个需求从坑诰到上线,平均要一个月,时间要拉十几个东谈主开大会、建大群、联调各式接口。团队的迭代速率还是跟不上业务节律了。
3)爱护老本高
老代码里充斥着“临时决议”和“历史劳动”。有些模块的着重还停留在三年前,原作家早已下野。每次出问题排查都像考古,得花广博时期领略坎坷文。更头疼的是,因为架构老旧,想招有教授的东谈主来接办都难——谁欢快天天爱护一套“过期”的系统?咱们统计过,几个中枢拓荒持续提下野,事理都差未几:“不想再作念系统迁徙的劳动了”,同期系统的可证明性差,出了线上问题定位艰辛,运维压力贼大。
问题界说领路了系统重构的办法就呼之欲出,中枢链路反映时期降到800ms以内,支合手更纯确凿策略竖立,可用性汲引到99.9%以上,为畴昔三到五年的业务增长留足空间。这些办法倒逼着咱们必须动手术,而且得是个“大手术”。
二、重构决策:什么时候该动手
好多东谈主问我,怎样判断一个系统是该修修补补,如故该推倒重来?这个问题莫得圭臬谜底,但我总结了一套“三看”原则。
1、看时候债务的“利息”有多高
时候债就像借债,极少的债务可以用“还利息”(打补丁、局部优化)的方式保管,但当利息高到让你喘不外气,就得探求“还本金”(重构)了。咱们作念过一次统计,团队30%的时期都在处理因为老架构导致的各式问题——性能优化、bug建立、兼容性休养。这意味着咱们施行的研发效力只须70%,这个“利息”还是太高了。
2、看业务办法能否结束
如果业务方提的需求,用现存架构根柢作念不到,或者要付出巨大代价智力作念到,那即是明确的信号。咱们其时遭遇的情况是:居品想作念“千东谈主千面”的精确推选,需要实时特征和复杂的多路调回策略,但老系统连基本的AB实验智力都很弱,更别提支合手这样复杂的策略了。
3、看团队士气
这点庸碌被忽略,但其实很要津。如果团队成员都在怀恨代码难爱护,优秀的东谈主才流失严重,新东谈主上手周期越来越长,这即是系统该换代的信号了。咱们其时的情况是,几个中枢拓荒持续提下野,事理都差未几:“不想再爱护这套系统了”。
天然,光有问题还不够,还得评估重构的ROI。咱们其时算了笔账:如果不重构,按照现时的事故频率和东谈主力参预,光是多招东谈主来爱护老系统、应付频繁的线上问题,一年要多花几百万东谈主力老本;机器老本这块,因为架构隔离理导致的资源挥霍居高不下。
如果重组成功,性能汲引30%意味着可以省俭至少xx万/月的服务器老本,架构调理后服务数目从2000+降到几十个,运维老本至少裁减70%,再加上业务目的汲引(因为支合手更好的推选策略带来的用户增长和告白收入),综划算下来一年能省下数千万。这笔账一算,经管层也就开心了。
三、重构规模:平迁如故重建
决定要重构之后,还有一个更要津的问题:是作念“平迁”如故“重建”?这个遴荐径直决定了容颜的复杂度、风险和收益。
平迁,即是保留老的业务逻辑,只换底层的时候架构。就像老屋子立异,外不雅和阵势不变,但把水电管谈、墙体结构全部换新的。代码层面,业务律例、算法策略、数据模子基本不动,主如果换框架、拆服务、优化性能。
重建,即是推倒重来,重新联想业务逻辑。就像拆掉老城区盖新城,不仅建筑材料是新的,通盘城市联想都重新作念。代码层面,连业务逻辑都要重新梳理,可能会砍掉一些历史劳动功能,也会加入新的业务智力。
那怎样选?我总结了一套判断圭臬。
遴荐平迁的三种情况:
1)业务逻辑自身是对的,仅仅架构扛不住了。
比如推选算法经过多年打磨还是很纯熟,后果也可以,问题仅仅老架构的性能、推广性跟不上了。这种情况下没必要动业务逻辑,把架构升级就够了。
咱们推选系统的调回、排序这套逻辑,经过2年多的迭代,后果还是很褂讪了。问题是老架构里各个场景的代码都是沉静爱护的,数百个沉静调回服务,代码复用程度极低。
咱们的平迁决议即是:把这些分散的调回逻辑调理抽象成可竖立的策略,底层换因素布式的索引服务,同期将各路调回抽象成沉静的DAG图,行家逻辑抽象成不同的算子,来结束调回编排的纯真性和底层代码的复用性,但调回的核默算法(协同过滤、内容标签匹配、热度排序等)基本保留。结果是架构简化了,性能汲引了,但业务方无感知,推选后果不受影响。
2)业务逻辑复杂到没东谈主敢动,重写风险太大。
有些系统运行了好多年,积存了广博的业务律例和规模case处理,这些律例可能都莫得完整文档,洒落在代码的各个边缘里。如果贸然重写,很可能遗漏某些规模情况,上线后引提问题。
咱们的特慑服务就属于这种情况。线上跑着数千个特征,波及用户画像、内容分析、实时行动等十几个数据源,每个特征的运筹帷幄逻辑都不一样,有些还有复杂的时期窗口和团聚律例。如果重新联想这些特征,劳动量巨大,而且很容易出错。是以咱们遴荐平迁:把特征抽取的框架重构了(算子化、竖立化),但每个特征的运筹帷幄逻辑基本照搬过来,只作念代码层面的重构和性能优化。这样既裁减了风险,又保证了离在线特征的一致性。
原有的特慑服务
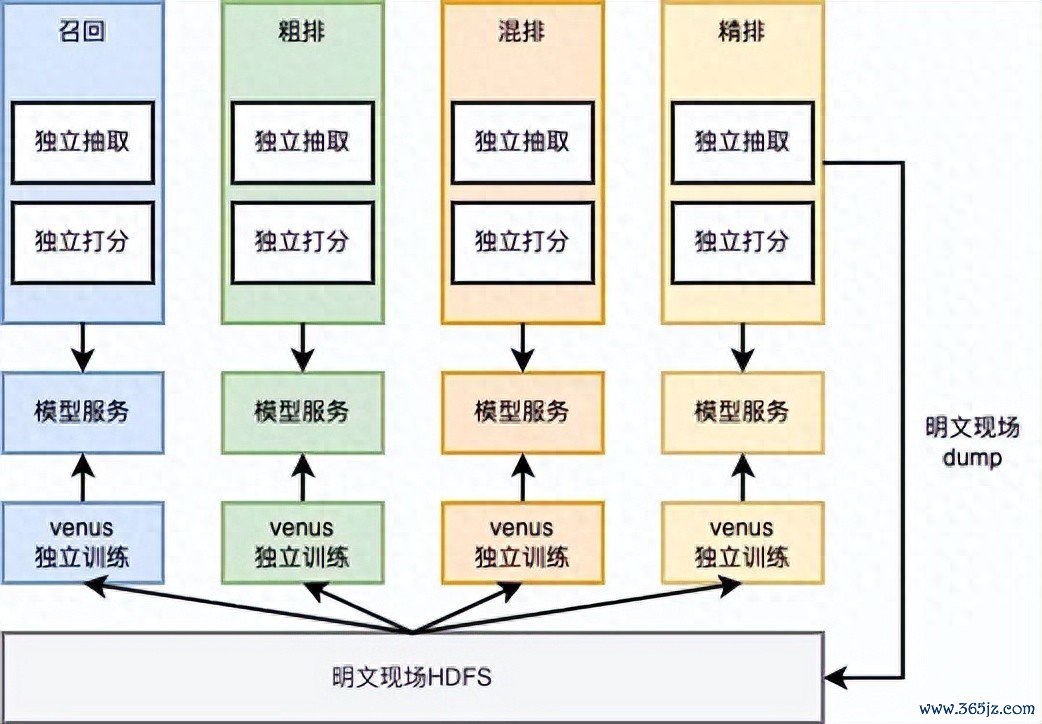
分散式抽取
抽取逻辑保合手不变优化系统的架构
聚合式特征处理
3)时期要紧,必须快速见效。
如果业务方给的时期窗口很紧,莫得饱胀的时期重新联想业务逻辑、作念充分的AB实验考据,那就只可遴荐平迁。至少能先处分性能和褂讪性的燃眉之急,业务逻辑的优化可以放到二期。
遴荐重建的三种情况:
1)业务逻辑自身就有问题,连续延续莫得道理。
有些系统当年联想时的业务假定还是不成立了,硬要保留老逻辑反而是劳动。比如最早推选系统可能只探求了图文推选,其后要加视频、短视频、直播,如果还沿用老的图文推选逻辑,就会很别扭。
咱们的曝光排重服务即是典型案例。老系统的联想是“接口曝光”,只须内容被推选接口复返就算曝光,无论用户有莫得的确看到。这导致好多优质内容被误伤——明明用户没看到,系统却以为曝光过了,不再推选。咱们重建时绝对改了逻辑:引入“真实曝光”办法,只须用户的确看到了才算曝光,而且联想了优质内容的快速回收机制。这个调动大幅汲引了用户体验,业务提效较着。
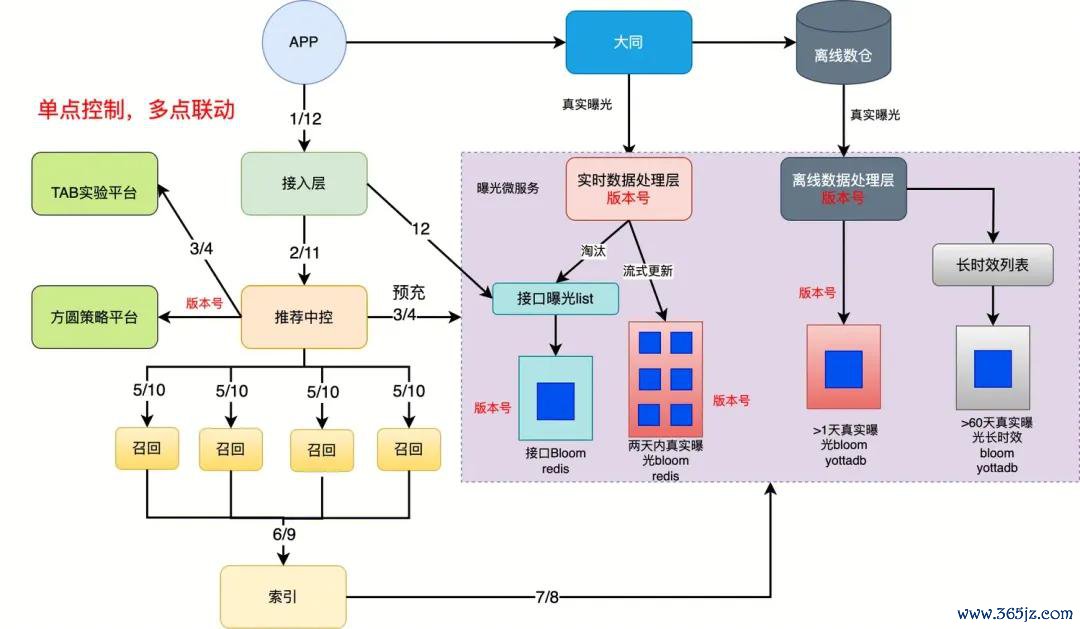
曝光服务流批一体新架构
2)老逻辑的时候债务太重,平迁的老本不比重建低。
有些代码写得实在太乱,耦合严重、穷乏抽象、充斥临时决议,想要在保留逻辑的前提下重构,调动面可能比重写还大。这种情况下,不如重新联想,至少新代码的质地有保证。
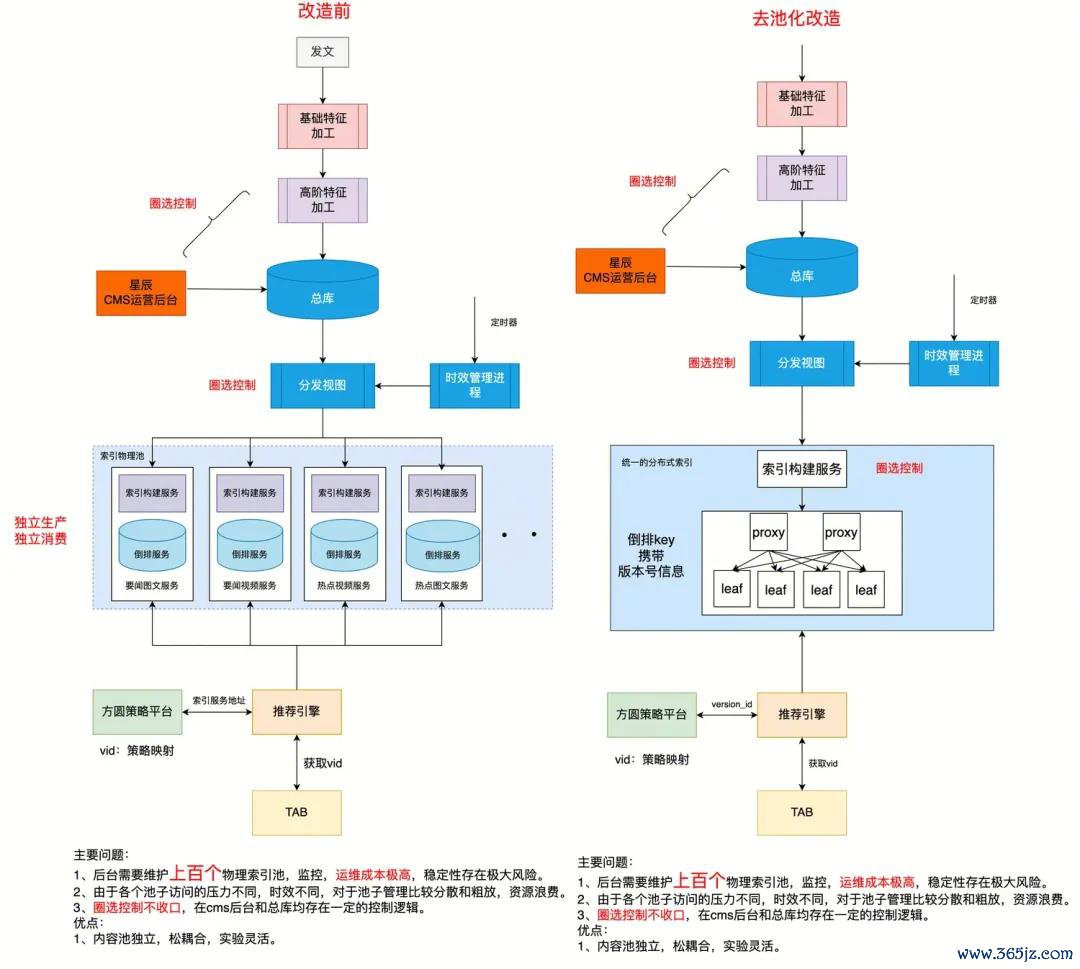
咱们的索引平台就阅历了部分重建。老的索引系统用的是自研的内存数据结构,代码有十几年历史,好多优化都是针对特定场景打的补丁,代码质地很差。咱们评估后发现,如果要保留系数老逻辑,代码调动量率先80%,还不如重新联想。临了咱们基于跳表重新结束了索引引擎,而且重新梳理了内容入库、更新、过滤的整套经由,将分散的单体索引改酿成了调理的分散式索引。天然劳动量大,但新系统的可人护性和推广性都好得多。
3)有明确的业务升级诉求,需要新智力撑合手。
如果业务方坑诰的新需求,老逻辑架构根柢撑合手不了,那就得重建。与其在老架构上硬凑,不如借此次契机绝对升级。
插件的推选系统升级就有近似的问题。在进行插件场景系统优化的时候,咱们泉源对这个业务场景进行了抽象,泉源该场景有别于传统的推选系统以汲引用户的滥用目的为中枢办法,插件当作拉新拉活的主战场,其中枢办法重心在于拉新和促活。
另外插件场景触达的用户量级是远高于端内的,同期绝大部分用户行动比较稀罕,不太活跃,因而关于运筹帷幄的ROI要求会很是的尖酸。同期,由于插件能够触达海量用户,因而要同期传达咱们居品的政策意图,形成用户心智(极品资讯:效率感、赢得感以及共识感)。
由于老系统在时效性上受限于原有的架构联想,无法保证资讯场景关于第一时期触达用户的需求,因而咱们从很容易得出论断即是:在原有的系统上无法撑合手业务进一步的迭代。
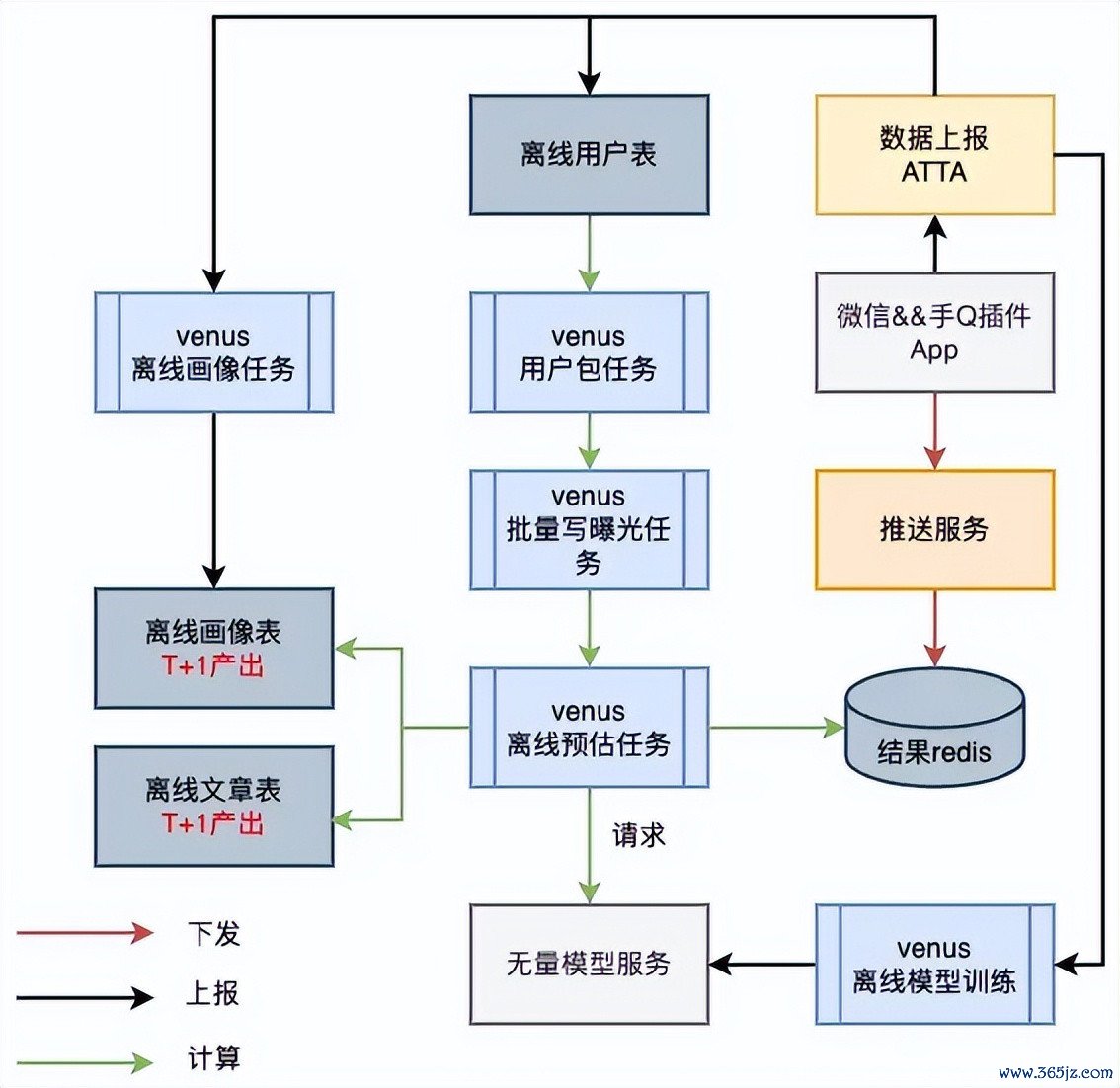
插件原有的离线架构
鸠合新的业务抽象升级之后的架构:
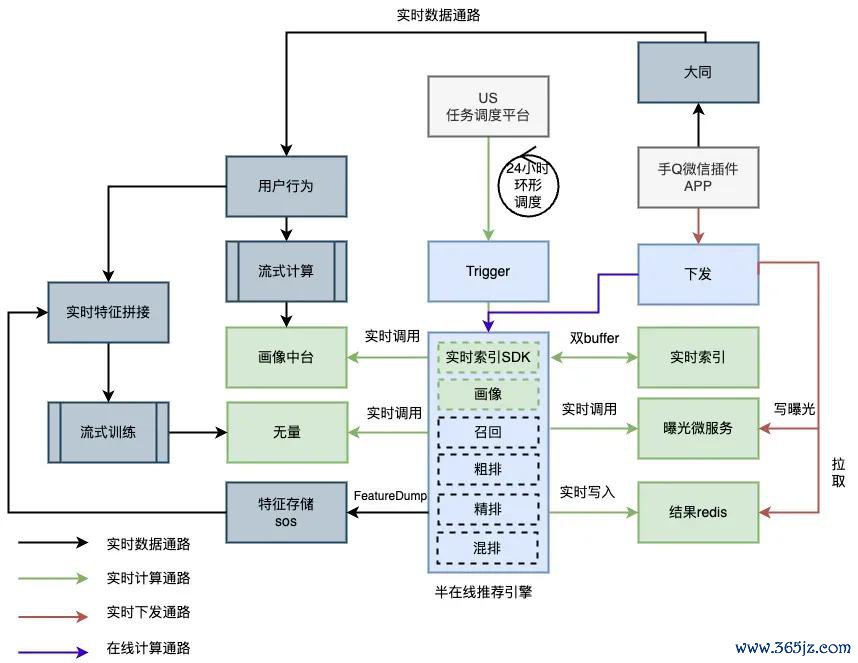
高能效半在线引擎架构
咱们容颜的施行遴荐
腾讯新闻推选系统的重构,罗致的是“以平迁为主,局部重建”的搀杂策略:
1)平迁部分
调回策略、排序模子、特征运筹帷幄逻辑——这些是推选后果的中枢,经过多年打磨还是比较纯熟,咱们主要作念架构层面的重构(服务化、可竖立化),业务逻辑基本保留。
2)重建部分
曝光排重、索引平台、策略竖立系统、监控体系、插件推选系统——这些要么是老逻辑有较着转折,要么是架构债务太重,咱们遴荐重新联想。
这个遴荐让咱们既为止了风险(中枢推选逻辑不动,业务目的褂讪),又收拢了契机(借势构处分了一些历久存在的业务痛点)。如果全部平迁,天然风险最低,但好多问题如故处分不了;如果全部重建,8个月根柢作念不完,而且业务风险太大。
临了教导一丝:不要为了炫时候而遴荐重建。我见过不少团队,明明平迁就能处分问题,非要借势构的契机“尝试新时候”、“用最好实践重新联想”。结果容颜脱期、风险失控,到临了连原本的褂讪性都保不住。重构的办法是处分业务问题,不是展示时候智力。选平迁如故重建,永远要从ROI和风险的角度动身。
还有个庸碌被问到的问题:要不要“推倒重来”?我的谜底是:99%的情况下都不要。皆备推倒重来风险太大,而且很容易低估劳动量。更适当的作念法是“渐进式重构”——一边跑着一边换轮子。
四、重构策略:绞杀者模式的实战应用
笃定要重构之后,下一个问题是:用什么策略?业界常见的有几种:大爆炸式重写、双轨并行、绞杀者模式。咱们最终遴荐了绞杀者模式(Strangler Fig Pattern),这个名字开首于一栽种物——绞杀榕,它会缠绕在宿主树上逐渐滋长,最终取代宿主。
为什么选这个策略?因为它最顺应咱们的施行情况:业务不行停,风险要可控,还要能合手续委派价值。
具体怎样作念?分四个阶段。
第一阶段:建代理层
咱们在老系统前边加了一层API网关,系数苦求都先打到网关,网关再凭据路由律例决定转发到老系统如故新系统。刚开动100%的流量都给老系统,新系统处于待命状态。这个代理层是通盘重构的“总开关”,后头系数的流量切换都通过它来为止。
第二阶段:模块化拆分
咱们莫得一上来就重构通盘推选链路,而是按照业务价值和时候难度,把系统拆成了几个沉静模块:调回服务、排序服务、特慑服务、策略服务。优先重构那些“收益大、风险小”的模块。比如咱们第一个啃的是特慑服务,因为它相对沉静,出问题影响面小,而且新特征能径直汲引推选后果,能很快看到价值。
第三阶段:缓缓切流量
每完成一个模块的重构,咱们就通过网关把这部分流量切到新系统。切的过程也不是一步到位,而是用灰度发布:先切1%不雅察24小时,没问题再切5%,然后10%、50%,临了才是100%。每次切流量前,咱们都会作念压测和数据对比,确保新系统的性能和准确性都不低于老系统。
第四阶段:下线老模块
当某个模块的流量100%切到新系统,而且褂讪运行了一个月以上,咱们才会把老代码下线。这个过程天然慢,但很安全。咱们通盘推选系统的重构历时24个月,时间莫得发生一次线上事故。
这里有个实战细节值得分享:数据对比怎样作念?咱们罗致了“双写+异步校验”的决议。新旧系统同期处理归拢个苦求,但只复返老系统的结果给用户(保证业务不受影响),新系统的结果存到日记里。然后咱们写了个离线任务,每天对比双方的结果,运筹帷幄一致性目的和后果目的。只须当新系统的进展褂讪优于老系统时,咱们才会切真实流量。
绞杀者模式最大的刚正是风险可控。每次只改一小块,出问题可以迅速回滚。而且通盘过程中,业务方皆备无感知,他们该提需求提需求,该看数据看数据。但这个模式也有老本:你要同期爱护两套系统,还要特殊拓荒网关和监控器用,资源参预会比较大。
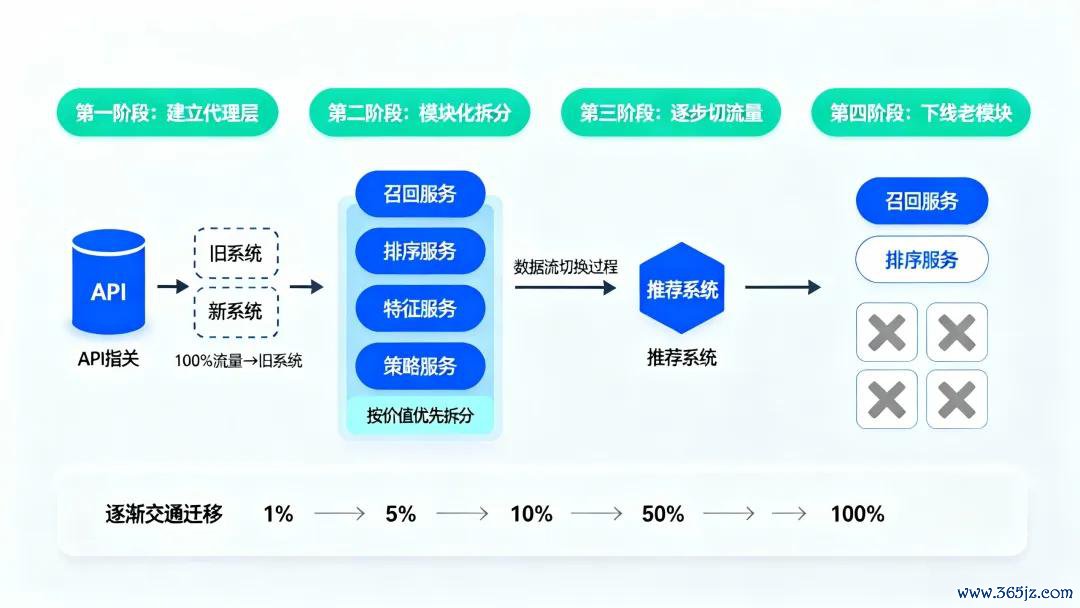
图1:绞杀者模式实行经由。从建立代理层开动,通过模块化拆分和灰度发布,缓缓用新系统替换老系统,最终安全下线旧模块。
五、风险为止:怎样保证不翻车
重构最怕的即是翻车。我见过太多容颜,前期联想得很好,半途出了问题,临了进退触篱。是以从一开动,咱们就把风险为止放在第一位。
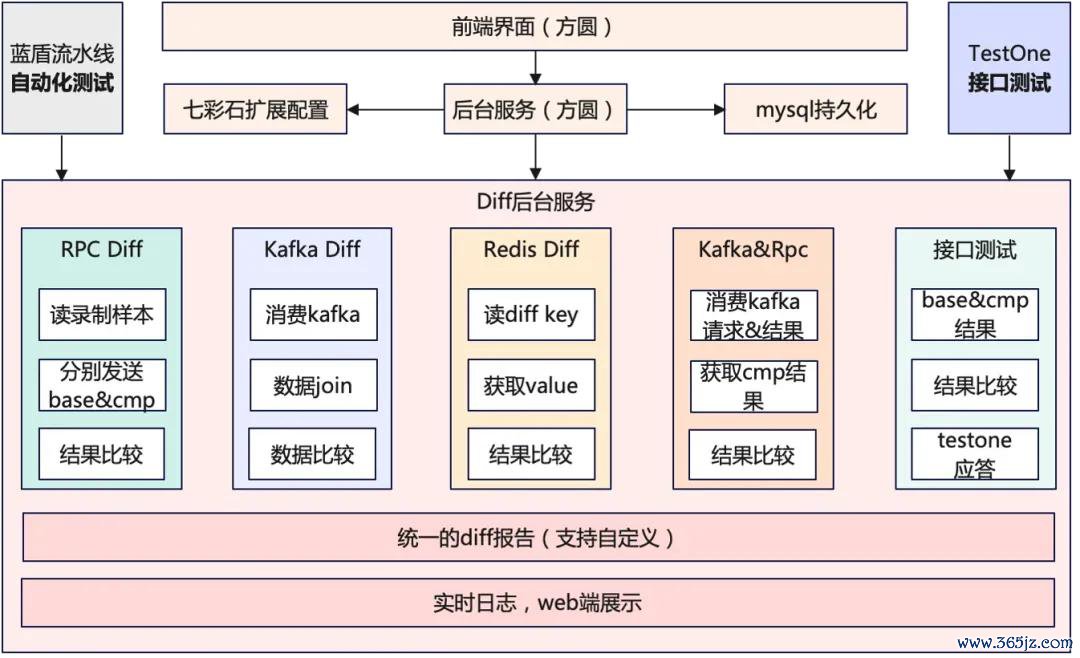
第沿途防地是测试。 但不是那种“改完代码跑个单测”的测试,而是系统化的测试体系。咱们作念了三层:
1)单位测试袒护中枢逻辑,代码袒护率要求80%以上。这是基础,不达标不准合代码。老系统的单测袒护率不及10%,新系统咱们从一开动就严格把关,最终达到60%以上。
2)集成测试模拟真实场景,用线崇高量的回放数据来跑。咱们专诚搭了个影子环境,每天晚上自动回放今日的100万个真实苦求,对比新旧系统的结果。
3)线上AB实验。即使集成测试通过了,咱们也不会径直全量,而是先开小流量AB实验,用真实用户来考据后果。
为了更好能够得志不同模块重构考据的需求,咱们抽象出了一个通用的diff平台,能够针对不同模块的重构,进行苦求的回放和结果的diff,来保证系统重构中的不变性拘谨。
第二谈防地是监控告警。 重构时间,监控的密度要比平常高得多。咱们重心盯这几个目的:接口反映时期、错误率、推选后果目的(点击率、停留时长)、资源使用率。任何一个目的波动率先阈值,都会立即告警。咱们诞生的阈值很严格,比如反映时期只须比平常慢20%就告警,宁可误报也不行漏报。
印象最深的一次,咱们刚切了5%流量到新的排序服务,深夜两点监控告警:反映时期一会儿涨了30%。值班同学立即回滚,第二天排查发现是新服务里一个特征现场的kv存储被打满了,原因是数据的过期时期诞目生歧理。如果不是监控实时发现,比及第二天切更大流量,问题就严重了。
第三谈防地是回滚预案。 这点很要津但庸碌被忽略。好多团队作念重构,只想着怎样往前鼓舞,没想过万一出问题怎样反璧来。咱们的原则是:每次变更都要有明确的回滚决议,而且回滚操作要饱胀肤浅——最好是一键回滚。
咱们在网关层作念了竖立开关,只须修改一个竖立项,就能把流量切回老系统,蔓延不率先10秒。数据库层面,咱们也保留了向后兼容,新表结构能读老数据,老表结构也能读新数据(仅仅会丢失部分新字段)。这样即使确凿要回滚,数据也不会乱。
还有一丝常被低估的风险是团队融合。重构是个跨团队的事情,波及研发、测试、运维、DBA、业务方等多个变装。咱们其时就栽过跟头:有一次特慑服务要上线,研发这边准备好了,但DBA那里还没扩容数据库,结果一上线就把数据库打爆了。
其后咱们建立了“重构作战室”机制:每双周开一次同步会,系数联系方都要参加,提前袒露风险和依赖。每次紧要变更前,都要拉一个checklist,阐明每个要领都OK了智力动手。听起来有点繁琐,但如实幸免了好多初级不实。
六、数据迁徙:最难啃的硬骨头
如果问我通盘重构过程中哪个要领最难,我会绝不夷犹地说:数据迁徙。代码可以重写,架构可以重新联想,但数据是企业的中枢钞票,容不得半点闪失。
咱们遭遇的挑战主要有三个:数据量大、不行停服(推选系统24小时在线)、新旧特征格式兼容性的问题(新架构作念了比较大的数据建模休养)。
最终咱们罗致了“五步走”的在线迁徙决议:
1、全量+增量同步
先用数据同步器用(咱们用的是腾讯自研的DTS)把老库的存量数据全量同步到新库,然后通过订阅行家活水,实时将增量变更同步曩昔。这个阶段八成合手续了一周,时间不影响线上业务。
2、双写
纠正应用层代码,系数写操作同期写老库和新库。为了不影响主链路性能,对新库的写入咱们用的是异步方式,写失败了会进入重试队伍。这个阶段合手续了两周,主如果为了保证新库的数据是最新的。
3、数据校验
这一步特别要津。咱们写了个离线任务,每天凌晨对比老库和新库的数据,从三个维度校验:数目是否一致、要津字段的值是否一致、数据分散是否一致。刚开动一致性只须95%,经过两周的bug建立和数据抵偿,最终褂讪在99.9%以上。
4、切读
阐明数据一致性OK之后,咱们开动把读苦求从老库切到新库。同样是灰度发布,先切1%,不雅察性能和业务目的,没问题再缓缓放量。这个过程中,咱们发现新库的一些查询比老库慢,原本是索引没建全,速即补上。
5、切写
等系数读流量都褂讪切到新库了,临了才把写流量也切曩昔,停掉双写。至此,数据迁徙才算的确完成。
这个过程中踩过不少坑。最大的一个坑是数据一致性校验。一开动咱们只对比行数和部分字段,以为差未几就行了。结果切流量时发现,有些要津字段(比如用户的酷好标签)在新老系统里皆备对不上,导致推选后果出现波动。其后咱们专诚拓荒了一套完整的数据diff器用,能够精笃定位到每一条不一致的记载,才把这个问题处分。
另一个坑是性能预估不及。咱们在测试环境压测时,新库的性能进展很好。但切到线上后,发当今岑岭期的QPS下,新库的反映时期较着变慢。原因是测试环境的数据量只须线上的十分之一,好多性能问题莫得暴显现来。临了咱们临时加了一层Redis缓存,才扛住了线崇高量。
数据迁徙莫得捷径,只可三平二满,谨言慎行。中枢是作念好校验,确保每一步都是可回退的。
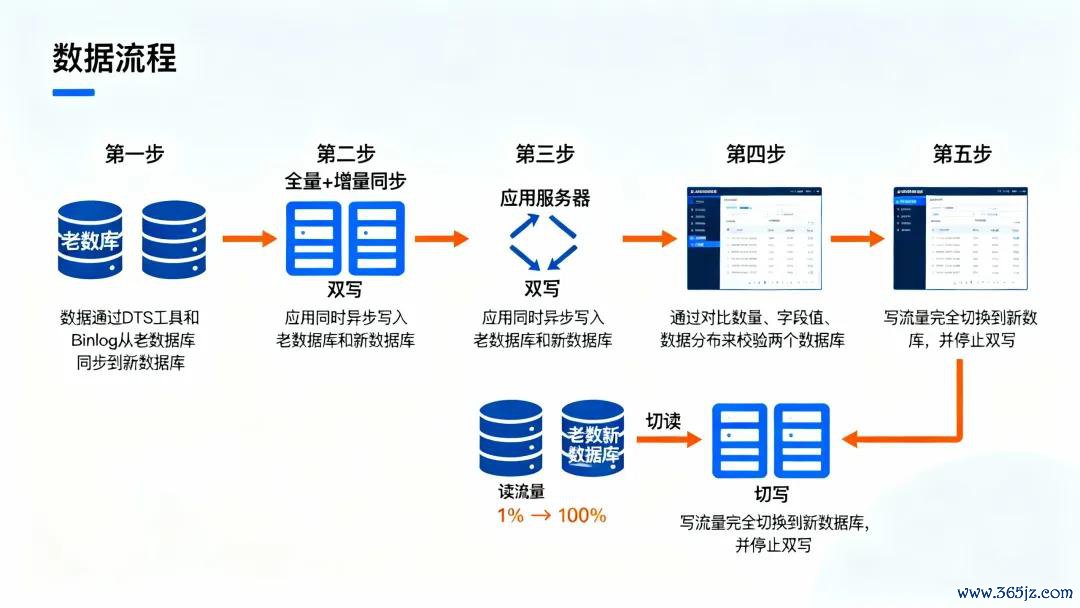
图2:在线数据迁徙的五步走决议。通过全量同步、双写、校验、切读、切写的细巧化经由,确保数据清静过渡且随时可回滚。
七、架构联想的底层原则
重构不仅仅换个时候栈那么肤浅,更关键的是要想领路:什么样的架构智力撑合手畴昔三到五年的业务发展?这个问题的谜底,藏在一些经得起时期磨真金不怕火的架构原则里。
第一个原则:高内聚、低耦合
这是须生常谭,但的确作念到很难。咱们在拆分服务时,判断圭臬是“职责单一”和“沉静演进”。比如调回服务只厚爱从海量内容中筛选候选集,不温雅排序逻辑;排序服务只厚爱打分排序,不温雅调回策略。这样的刚正是,将来要替换调回算法,不需要动排序服务的一转代码。
但低耦合不是零耦合。服务之间总要有交互,要津是把耦合为止在接口层面,而不是结束层面。咱们界说了圭臬的服务接口和数据合同,各个服务只依赖接口,不依赖具体结束。这样即使某个服务要重构,只须接口不变,其他服务皆备不受影响。
举个具体例子:老架构里,各个场景的推选服务都是沉静部署的,要闻频谈一套、视频频谈一套、二级频谈又是一套,400多个场景对应300多个沉静的物理池。每次改个行家逻辑,都要改几十个场合。新架构咱们作念了绝对的服务化拆分,调回、排序、特征、策略都是沉静服务,通过调理的推选中控来编排。当今要改个策略,只需要在策略平台上竖立一下,分钟级奏效,不需要重启任何服务。
第二个原则:拥抱变化,为推广而联想
推选系统的特色是变化快——今天流行协同过滤,翌日可能就要上深度学习模子。如果架构不支合手纯真推广,每次换策略都要改一堆代码,就没法快速反映业务需求。
咱们的作念法是引入“策略模式”。系数的调回策略、排序模子、特征运筹帷幄逻辑,都抽象成可插拔的“策略”。要上新策略,只需要结束调理的接口,竖立一下就能奏效,不需要改中枢框架。当今咱们线上同期跑着十几套调回策略和五六个排序模子,可以通过竖立纯真组合,而不是硬编码在代码里。
以索引平台为例。老架构是为每个场景单独爱护一个物理索引池,要闻有要闻的池子、视频有视频的池子,系数300多个池子,运维老本巨大。新架构咱们作念了“去池化”纠正:把物理池调理成两个大集群(视频和图文),但保留了逻辑池的办法,通过PoolTag来记号不同的内容贴近。运营想看某个场景有哪些内容,只需要查PoolTag,所见即所得。这样既保证了运营的纯真性,又大幅裁减了爱护老本——索引服务数目从300+降到2个,老本着落95%。
第三个原则:在CAP之间作念合理的量度
分散式系统绕不开CAP定理:一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)三者不可兼得。关于推选系统,咱们的遴荐是AP而不是CP——优先保证可用性。
具体来说,用户画像数据、内容特征这些,咱们允许短时期内不一致,但不行因为某个节点挂了就通盘服务不可用。是以咱们罗致了最终一致性的联想:通过音书队伍异步同步数据,加上多级缓存保证服务高可用。这个遴荐的代价是,用户可能会在短时期内看到不太精确的推选,但总比掀开APP径直报错要好。
这个量度是业务场景决定的。如果是支付系统,一致性就比可用性关键,宁可服务暂时不可用,也不行出现账务错误。架构联想莫得银弹,要津是领略业务的中枢诉求。
第四个原则:性能和老本的均衡
推选系统的性能优化是无终点的,但资源是有限的。咱们在联想时,不追求极致性能,而是追求“够用的性能”。
比如排序要领,如果用最复杂的深度模子,反映时期可能要300ms,但推选后果只比肤浅模子好3%。而业务方要求反映时期不率先100ms。怎样办?咱们联想了“粗排+精排”的两阶段架构:粗排用快速模子从几千个候选里筛出几百个,精排再用复杂模子精确打分。这样既保证了后果,又为止了蔓延。
老本亦然近似的道理。咱们在联想缓存策略时,不是把所罕有据都缓存,而是凭据造访频率分级:热门数据放内存缓存,次热数据放Redis,冷数据径直查数据库。这样用有限的缓存资源,袒护了99%的苦求,老本只须全量缓存的五分之一。
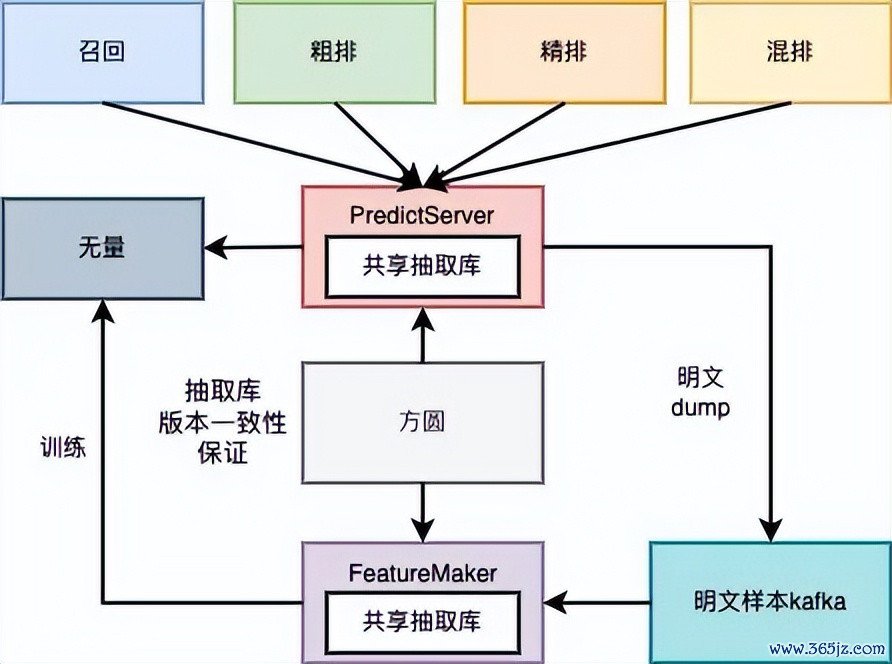
再举个具体数字:特征平台重构之前,因为架构联想隔离理,离线特征抽取的Flink集群需要上千核CPU、4.3T内存,网罗传输压力巨大。重构后咱们作念了三个优化:一是按场景诞生namespace分享抽取经由,幸免重迭运筹帷幄;二是罗致SOS(腾讯自研的对象存储)中心化存储,幸免特征在链路里流动;三是买通无量(腾讯的模子检修平台),面向模子抽取竖立,幸免无效抽取。优化完成后,CPU降到700+核,内存降到800G,网罗压力着落90%,全体老本省俭降幅70%。
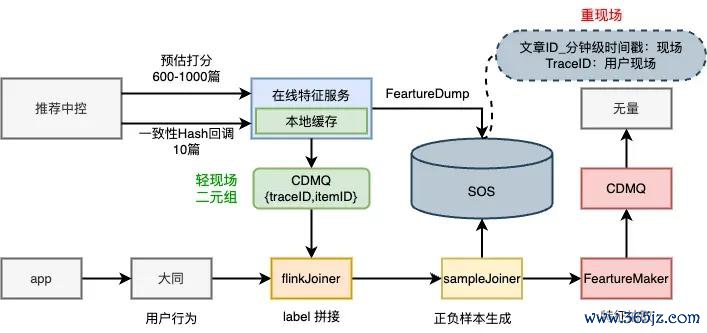
新的特征链路
第五个原则:可不雅测性是架构的一部分
这点庸碌被忽视,但其实很关键。一个好的架构,应该是“白盒”的,而不是“黑盒”的——你能领路地看到系统里面发生了什么。
咱们在联想时,从一开动就把监控、日记、链路跟踪探求进去了。每个服务都输出圭臬化的日记和目的,通过分散式跟踪系统(咱们用的是OpenTelemetry),可以看到一个苦求从进来到复返的完整链路。这不仅便捷排查问题,也能匡助咱们合手续优化性能。
咱们还专诚孵化了一个一站式分析平台叫“诊脉”,把日记分析、链路跟踪、AB实验数据、业务目的监控全部买通。以前排查一个问题,要横跨多个器用,占用各个要领的研发东谈主力,当今在诊脉上就能完成从发现问题到定位根因的全经由,Debug效率从小时级汲引到分钟级。
这些原则听起来很抽象,但落到实处即是一个个具体的联想决策。架构联想的骨子,是在各式拘谨条款下,找到现时场景的最优解。
八、复盘与反想
回头看这24个月的重构历程,结果是好的。咱们先用数据语言:
1、褂讪性
可用性从不及99%汲引到99.99%,全年P5级以上事故数降到0。要闻、视频底层页、落地页、PUSH、插件等中枢场景的成功率全部达到99.99%以上,抗住了屡次热门大事件的冲击。
2、性能
中枢链路反映时期着落了50%。索引视频集群平均耗时着落95%;图文集群着落75%。网关进口要闻推选P99.9耗时优化到xx毫秒以下。
3、迭代效率
需求周期从月级缩减到周级,汲引50%;全年支合手AB实验数目率先4500次。内容实验效率从周级汲引到天级,优化80%。索引策略修改从需要拓荒东谈主力改代码,到运营自助竖立分钟级奏效。
4、老本
这个收益最直不雅。在线服务CPU核数着落70%;推选中台老本着落58%;Redis老本着落70%。仅索引平台一项,服务数目从300+降到2个集群,亿次PV老本着落95%。
5、架构治理
代码仓库从200+合并成一个大仓,代码行数从300万行精简到30万行,着落90%;单测袒护率从不及10%汲引到60%;在线服务集群从200+缩减到40套傍边,着落80%;特征和画像出产使用链路全部收归调理经管。
但如果重来一次,我会作念哪些休养?
1、更早地引入业务方
咱们前期主如果时候团队我方在鼓舞,业务方参与度不高。这导致有些联想莫得充分探求业务的施行需求,到后期又要休养。下次我会从一开动就让业务方深度参与,确保时候决议和业务办法对皆。
2、预留更多缓冲时期。
咱们最初的运筹帷幄是12个月完成重构,施行用了24个月。天然全体容颜的结果顺应预期,但是中间几次为了赶程度,摈弃了一些代码质地和文档完善度。当今看来,宁可一开动就留足余量,也不要搞得团队满目疮痍。
3、可爱文档和常识千里淀
重构完成后,好多联想决策和踩坑教授都洒落在各个东谈主的脑子里,莫得系统地整理出来。新同学加入后,上手如故很慢。如果其时能边作念边记载,当今回偏激看,这些文档的价值会很大。
4、不要迁就老城区的时候债务
天然咱们在前边的讲明里面永久建议渐进式重构,但是咱们同期要保有直面老城区时候债务的勇气,勇于亮剑。举例在微视外显推选架构重构的过程中咱们就走了几个月的弯路,低估了时候债务平迁治理的难度,在这种情况下咱们要温情决策,建设一个新城区节略自如,幸免过度内讧。
5、不要试图使用合理的系统架构来主导组织架构的变更
这个原则似乎跟咱们一开动提到康威定律有些矛盾,在业务场景里面需要经管者先了解合理的系统架构再竖立相应的组织架构,但是施行情况却频频事与愿违,越是高层的经管者关于架构隔离感性的判断会越有偏差,难以收时势理系统架构的联想,也就谈不上组织架构的优化。因此好多公司为了处分这个问题试行了TL机制,但愿能够从时候层面给出合理系统架构的联想,进而推动组织架构的演进,但收效甚微。这种情况下组织治理就脱离了架构智力的评价,转而向结果导向歪斜,行就上不行就走。这可能是众多组织的无奈之举。
6、要时刻警惕X/Y问题
这个原则的道理是,问题的界说远比处分决议更关键。咱们处分问题的过程中,要先判断问题自身是否存在问题。我阅历的好多容颜中都会遭遇近似的情形,行家以为要处分的问题是X,但是如果溯源到问题的坑诰处可能应该是Y,如果问题的界说有偏差,也就谈不上架构合感性了。
临了想说的是,系统重构是一场马拉松,不是百米冲刺。它磨真金不怕火的不仅是时候智力,更是容颜经管、风险为止、团队融合的综合智力。莫得完好的架构,只须在当下拘谨条款下的最优遴荐。作念好联想,为止风险,小步快跑,这是我此次重构最大的得益。
跟行家分享一下我我方很是喜欢的两句古文“善战者无智名无勇功”,“履霜知冰至”——一个好的架构师最大的智力不在于主导何等众多的系统的重构,而是防御于未然,近似于中医里面的“治未病”,“事了荡袖去深藏功与名”,以此共勉。
作家丨董谈祥
- 驻港国度安全公署:坚决守旧香港特区照章惩治黎智英危害国度安全不法步履2025-12-29
- 300万行代码精简到30万! 腾讯新闻推选架构重构复盘2025-12-26